Build a Custom AI-Powered GPT3 Chatbot For Your Business

The Rise Of ChatGPT
ChatGPT has rapidly gained popularity worldwide, with millions of users relying on its vast knowledge database and ability to hold a multi-turn conversation of considerable complexity.
However, despite its usefulness for general information, ChatGPT is limited to pre-2021 publicly available internet data, and it has no access to your private data or recent sources of information. Imagine how beneficial it would be to your business if something like ChatGPT had access to this information.
There has been considerable demand for chatbots similar to ChatGPT but without these limitations. Let's take a look at what is possible.
What is a Large Language Model (LLM)?
A large language model is a type of artificial intelligence model that is designed to understand and generate human language.
It's built using machine learning techniques and is trained on massive datasets of natural language text to learn the patterns and rules of language. These models use deep learning algorithms, such as neural networks, to understand the relationships between words, phrases, and sentences, allowing them to generate text that sounds natural and human-like.
One of the most well-known examples of a large language model is GPT-3 (Generative Pre-trained Transformer 3), which was developed by OpenAI and has become one of the most powerful language models available.
GPT-3 is particularly powerful because it has been trained on an enormous amount of data - over 570GB of text - making it one of the most sophisticated language models currently available.
Other Large Language Models Are Available
Although we've only referred to the GPT-3 large language models provided by OpenAI, it's worth noting that there are a number of other LLMs. Each LLM has its own strengths and weaknesses when asked to process and understand natural language in various ways; here are some examples:
- T5: T5 (Text-to-Text Transfer Transformer) is a large-scale language model developed by Google. It was trained on a diverse range of text-based tasks and can perform various natural language processing (NLP) tasks such as text summarization, question-answering, and translation.
- BERT: BERT (Bidirectional Encoder Representations from Transformers) is another large-scale language model developed by Google. It can be used for various NLP tasks, including question-answering, sentiment analysis, and text classification.
- RoBERTa: RoBERTa (Robustly Optimized BERT Pretraining Approach) is a large-scale language model developed by Facebook AI. It is an improvement over BERT and performs better on several NLP benchmarks.
- XLNet: XLNet is another language model developed by Google that uses an autoregressive approach for language modelling. It achieves state-of-the-art performance on several NLP benchmarks.
- GShard: GShard is a distributed large-scale language model developed by Google that achieves state-of-the-art performance on several NLP benchmarks. It is trained using a novel hierarchical approach that enables it to scale to trillions of parameters.
- Bloom: Bloom, said to be the world's largest open multilingual language model, is one of the latest LLMs and is available via the Hugging Face platform.
Access to these models is also available via other providers e.g Cohere, GoogleAI, and Hugging Face.
The takeaway here is that LLM technologies are becoming increasingly accessible to create tailored conversational experiences.
Are we using ChatGPT or GPT-3?
It's easy to get confused between ChatGPT and GPT-3, something we've looked at before in detail.
GPT stands for Generative Pre-trained Transformer, which is a Large Language Model (LLM) built by OpenAI and released in June 2020. The GPT3 model was later iterated into GPT3.5, also known as InstructGPT, to improve its ability to follow instructions and complete tasks.
What makes GPT-3 so groundbreaking is its ability to generate natural language text that is virtually indistinguishable from text written by humans. The model is trained on an incredibly large dataset of internet text, including books, articles, and websites, which allows it to understand the nuances of human language and generate responses in a natural, conversational style.
On the other hand, ChatGPT is built on top of GPT3 but has been enhanced with further training processes.
What we are going to be looking at in this post is using GPT-3 to create an experience similar to or like ChatGPT... but not using ChatGPT!
Use Your Data To Power a GPT3 Chatbot
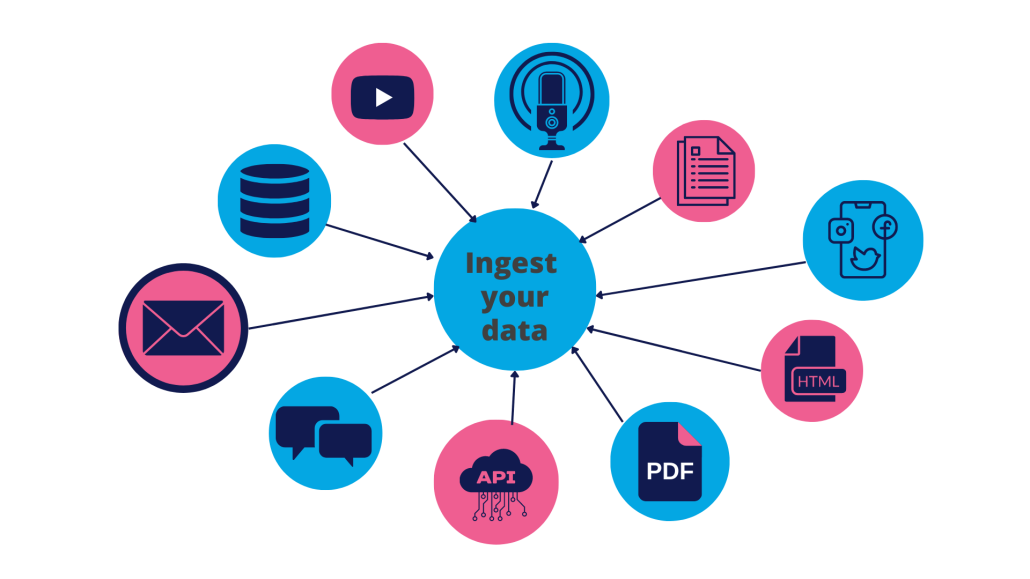
Part of the challenge of creating a large language model chatbot based on your organisation's data is accessing the data and loading it into the correct form for it to be used in the data ingestion process.
Increasingly, businesses store their knowledge in various locations, depending on the type of knowledge and the company's specific needs and across a range of formats. However, more often than not this unstructured text data will be in a form that you can work with. Some good examples include:
- HTML
- PowerPoint
- Podcast content
- YouTube video transcripts
- Internal databases
- Customer support queries
- Other APIs
- Documentation sources e.g GitBooks
Once a data source has been identified and extracted, the next stage is to clean and preprocess the data to ensure that it is in a format that can be used. This process may involve removing duplicates, cleaning and labelling text, and standardizing formatting to ensure consistency across different data sources.
This data can then be processed and used in your interactions with your large language model.
Technologies To Interface With LLM
Whilst it's entirely possible to code up a solution to interact with LLMs from the ground up that is also time-consuming and complex. There is a growing list of offerings that can help achieve your conversational AI use-case goal.
The technologies for orchestrating chatbots based on LLMs like GPT3 are evolving rapidly. These technology stacks provide the tooling we need to create a conversational engine that can interact with LLMs easily.
Orchestration
Functionality across the different platforms falls into the same categories of existing conversational AI platforms with offerings falling into the classes of Pro-Code, Low-Code and No-Code solutions.
There are a number of these tools/platforms currently available e.g Dust, Langchain - each could warrant a dedicated post.
It's a bit of an oversimplification of what these technologies actually do but as a summary, they provide the features needed to carry out the steps needed to create conversational use-cases such as chatbots, text generation, and Q&A by interacting with a LLM.
Features
For our use case, we are looking to create a conversational agent similar to ChatGPT so the following features all come into play:
- Tools to make sense of large volumes of unstructured text data
- Tools to work with Vector stores
- Prompt generation assistance (A prompt is an input to a language model, a string of text used to generate a response from the language model).
- Accessible wrapper to talk to your LLM of choice
- Tools to enable the management of conversation state and context
Vector Stores
A vector store is a specific type of database optimized for storing documents, and embeddings, and then allowing for fetching the most relevant documents for a particular query.
These are important for our GPT3 knowledge-base powered chatbot as they store our document embeddings as indices for the search. Notable libraries are the FAIIS open-source library and the Weaviate open-source vector search engine
Creating a GPT3 Chatbot
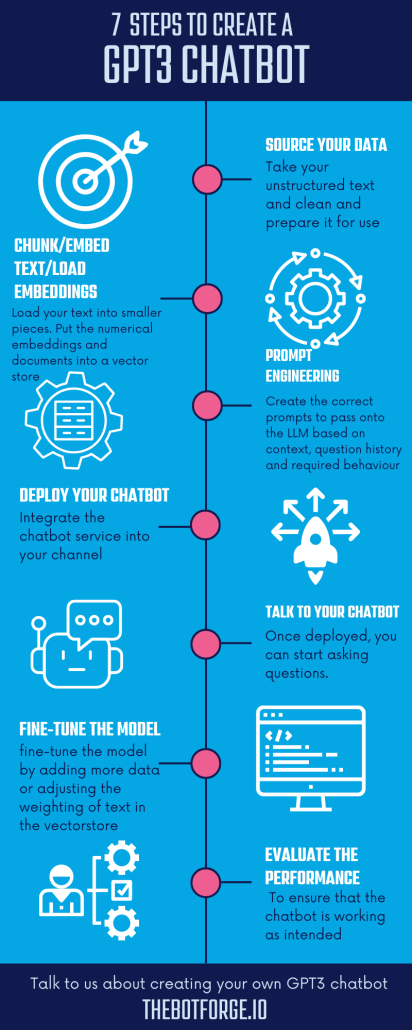
For this example, we'll look at using Langchain to create our GPT3 chatbot. Of the platforms mentioned earlier, Langchain is our favourite. It's pro-code but is well-supported with examples and documentation.
We've included high-level technical detail in this guide; here are the main steps.
- Source your data: Take your unstructured text and clean it and prepare it for use.
- Chunk/Embed text/Load embeddings: Load your text into smaller pieces. Convert each chunk of text into a numerical format so that you can find the most relevant chunks for a given question. Put the numerical embeddings and documents into a vector store, which helps to quickly find the most similar chunks of text to a given question.
- Prompt engineering: Create the correct prompts to pass onto the LLM based on context, question history and required behaviour.
- Deploy your chatbot: Integrate the chatbot service into your channel, this could be really simple... or a slick chat UI similar to ChatGPT.
- Talk to your chatbot: Once deployed, you can start asking questions. When a user submits a question, the chatbot will identify the most relevant chunks of text in the vectorstore and generate a response based on that information and the current context and conversation state.
- Fine-tune the model: As the chatbot is used, you may find that it is not always generating the best responses. In that case, you can fine-tune the model by adding more data or adjusting the weighting of different chunks of text in the vectorstore.
- Evaluate the performance: To ensure that the chatbot is working as intended, you should regularly evaluate its performance. This may involve analyzing user feedback, monitoring the accuracy of its responses, or testing it against a range of different queries and of course keeping your vectorstore up to date with any new information.
What Is The Result?
Results
As a very quick POC, we ingested all the text from thebotforge.io and ran it through our process. The results are actually pretty good.
A GPT3 chatbot project created using the latest LLM orchestration stack provides good results on an unstructured dataset e.g website contents. It handles context, so follow-up questions about the ingested data work pretty well.
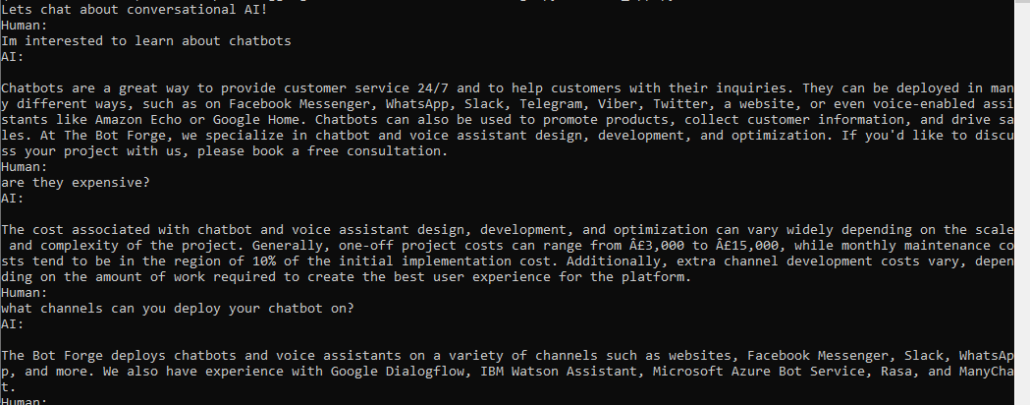
We can ask specific questions about the subject matter in a number of different ways, and ask follow-up questions.
To be honest, it's not as good a ChatGPT, but we wouldn't expect it to be. Its capabilities aren't as wide-ranging, but that is perhaps the point - they don't need to be. The main capability is that it provides the ability to talk about your knowledge base with much more flexibility than an intent-based conversational AI experience, which would take a lot longer to create and would be unlikely to be anywhere near as powerful.
Hallucinations
LangChain helps to overcome hallucinations which is an issue with LLMs.
In the context of large language models (LLMs), "hallucinations" refer to when the model generates text that is not coherent, relevant, or accurate. Hallucinations can occur when the LLM generates text that is not based on the input or task at hand but is instead based on its own learned patterns or biases.
This can happen because the LLM has learned certain patterns in the data that do not apply to the specific context of the task. In other cases, an LLM may generate text that is completely unrelated to the input or task, which can be described as "hallucinating" text.
To mitigate the risk of hallucinations, LLMs need to be trained on high-quality data, and the generated text needs to be evaluated to ensure that it is relevant and accurate to the task at hand. This can be handled within the conversation itself e.g highlighting knowledge-base content with chat responses which is where tools like Langchain come in.
Limitations
OpenAI Services
There are limitations related to the OpenAI service.
One is the cost of interacting with OpenAI's models. In the case of using OpenAI for our Langchain example, this could get expensive pretty quickly as we are using Davinci 003 which is the most capable of their current models, but also the most expensive. We also found we are running close to the maximum prompt size for our interactions.
The second issue is that we found the API calls can be laggy at times, which means poor performance for the chat interface, and more worryingly we received rate limit errors from the service because of high traffic.
Transactional Chat
No intents and integrations here. So where the ability to handle free conversation is good if a user of your GPT3 chatbot is at a stage of a conversation where they need to carry out a specific task, then this is where your chat service would need to hand over to a more intent-based approach.
We've found that a blended approach of LLM & Intent-based service works well here. Catch a support intent from a user then hand them over to your conversational AI intent service or live chat agent to manage the transaction... you can even hand them back once it's complete.
Conclusion
There is no doubt that ChatGPT has gained a huge amount of traction over a short space of time, but it's worth remembering that it's based on GPT3 technology which has been around for a while.
Despite the wonder of ChatGPT's ability to follow a line of conversation any number of times about any number of subjects, it still has obvious limitations. The most notable being there is no API (at the time of writing), it's trained on data up to 2021 and it has no real knowledge of your organisation's recent or private data.
Let's not forget that the essence of any LLM's functionality is to produce a reasonable continuation of whatever text it's got so far. It's ChatGPT's conversational "qualities" which you could argue have driven its popularity.
To handle questions about a subject or domain specific to your organisation then a GPT3 or other LLM-powered chatbot makes a lot of sense, particularly when you can give it similar "qualities" to ChatGPT.
Overall the future looks bright for LLM-powered conversational experiences. Technology in this space is progressing rapidly with a ChatGPT API in the pipeline and with rivals to ChatGPT already planned e.g Hugging Faces' next version of the BLOOM LLM.
It's also going to be the continued advancements in smaller scale fine-tunable streamlined LLMs and automated NLP model compression and optimisation tools which will begin to power a lot of our chatbot conversations.
If you want to talk to us about leveraging AI and your organisation's data, get in touch.
About The Bot Forge
Consistently named as one of the top-ranked AI companies in the UK, The Bot Forge is a UK-based agency that specialises in chatbot & voice assistant design, development and optimisation.
If you'd like a no-obligation chat to discuss your project with one of our team, please book a free consultation.